Why AI agents need environments
AI coding agents like Claude Code and Codex CLI can help devs write code incredibly fast. But there’s a lot of testing and review that needs to happen before you can ship this agent-written code. Without on-demand infrastructure, teams aren’t actually improving their deployment velocity.
When an agent writes a feature or fixes a bug, it needs to verify the code actually works:
- Does it run?
- Do the tests pass?
- Does it break anything else?
Without real environments to test/review, agents are writing code blindly. Teams end up reviewing PRs that look fine but fail the moment they hit staging.
If agents are writing 30-40% of your code, you need to trust the code works before human review. Otherwise, you’re just moving the bottleneck from writing to reviewing. When you define a code/test/review/repeat process for your agents, environments can give them the feedback they need to iterate on their own.
How environments enable AI agent workflows
Environments let agents write code, validate, test, and get feedback.
With on-demand environments, an agent generates code, pushes to a branch, and an environment spins up automatically, responding to a GitOps event. The agent runs tests, checks the app starts, and interacts with the UI or API to validate behavior. If something breaks, the agent reads the error and fixes it.
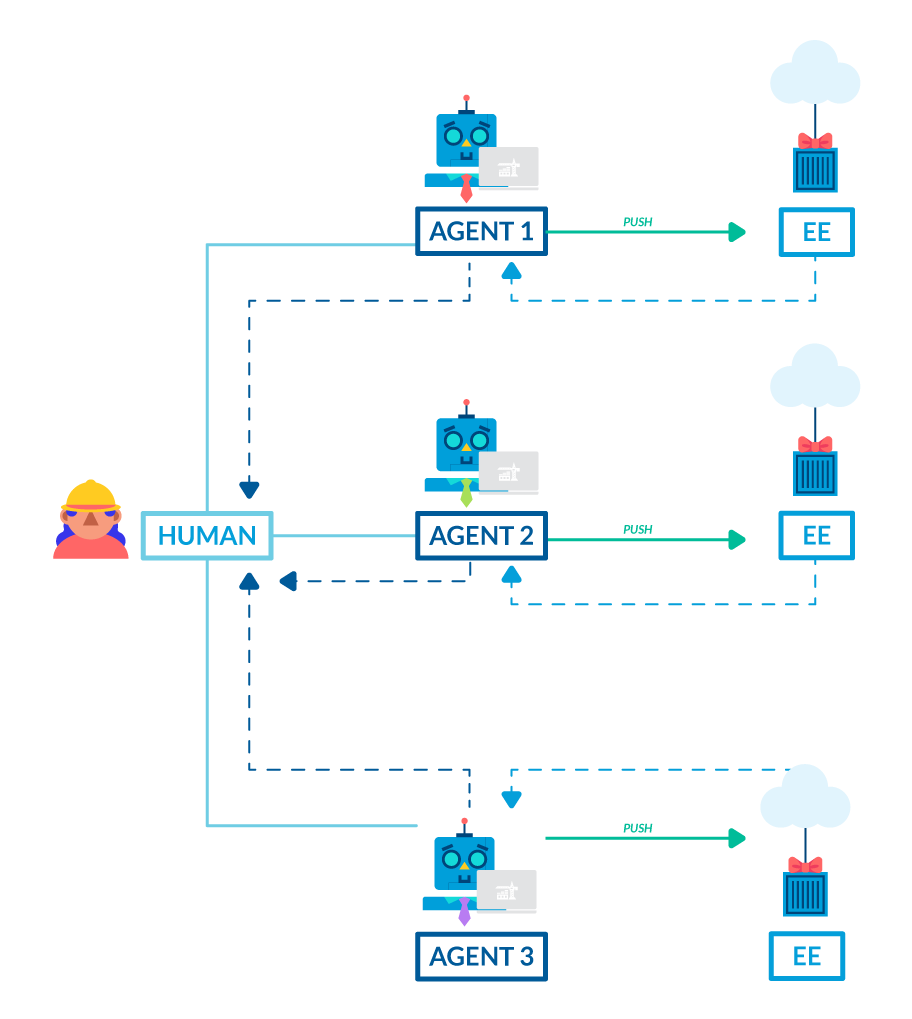
You can’t do this locally, because local envs are inconsistent (e.g. the “works on my machine” issue). For realistic results, you need your real services, data, and dependencies.
Many teams report cutting agent-written PR review time significantly once agents can self-validate in real environments.
Environments as a feedback loop for AI agents
The most valuable thing an environment gives an agent is info: error messages, test results, build logs, and a live app to visit.
Agents can then act on this feedback. They can find a failing test, read the error, and try to resolve. Or they might notice that a service won’t start, so they can check its logs and fix the config. The agent might iterate 5-10 times before a PR is ready for review.
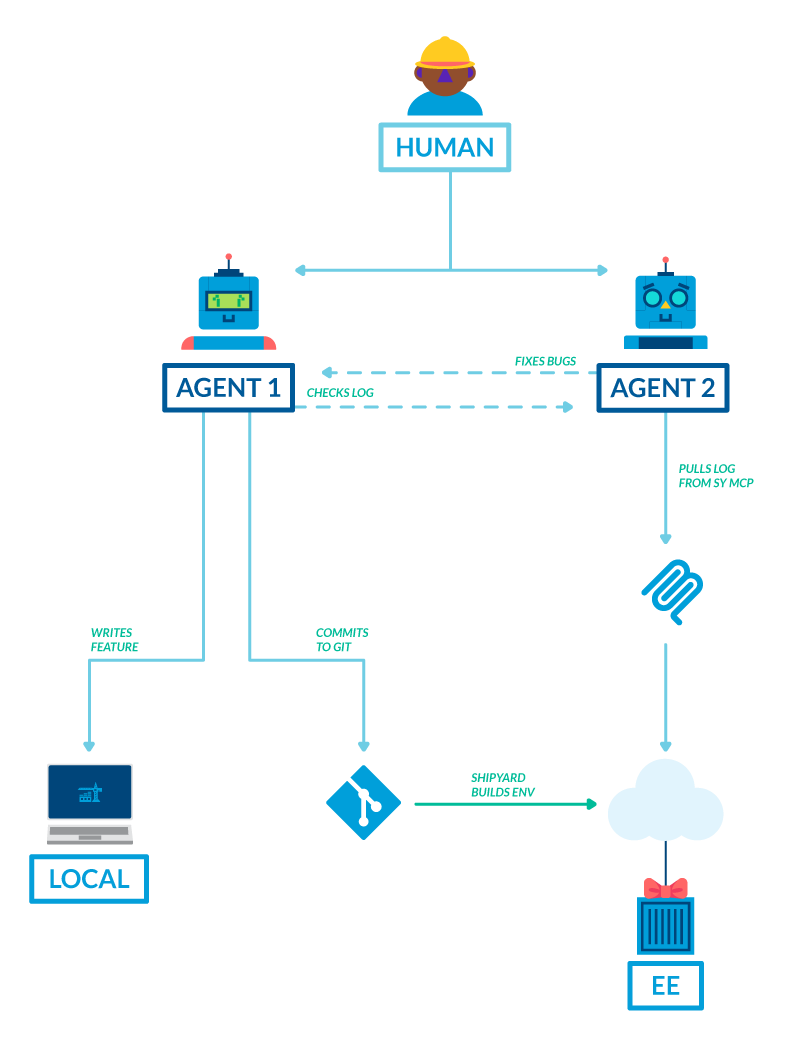
Without environments, agents aren’t able to proof/refine their code, and might often open a broken PR. When you give them environments, they can validate code continuously until it works.
When teams adopt environments for AI agents
Most teams adopt environments for AI agents at one of two points:
Early in AI adoption: Teams who want AI to work from the start. They know agent-written code needs testing infra, so they set up ephemeral environments before the code volume gets overwhelming and starts bottlenecking.
After feature velocity starts to slow: Teams who started building with agents but saw a plateau when agent-written code started breaking staging or requiring rework. At 20-30 PRs per week from agents, manual validation usually can’t keep up.
If agents generate code for 50+ PRs per month and each PR needs 30+ minutes of validation/rework, teams lose 25+ hours of engineering time to just that. When teams get to this level, they tend to not see any velocity improvements from adopting agents altogether.
Shipyard: environments for AI agents
Shipyard gives AI agents infra to self-test and self-validate their code. Agents can run tests, check builds, interact with services, and iterate autonomously.
Claude Code (and any MCP-compatible agent) integrates with Shipyard via the Shipyard MCP.
If you’re using AI agents, they’ll need real environments to reach their full capacity. Try Shipyard free for 30 days, or book a demo to see how it works with your setup.